[LG Aimers] 강화학습6 - Policy Gradient
LG Aimers 학습 내용을 정리한 글입니다.
Policy-Based RL의 장단점
장점
- 더 좋은 Convergence property를 가진다.
- high-dimentional/continuous action spaces를 가질 때 효율적이다.
- Stochastic policy를 학습하는 것이 가능하다.
단점
- 보통은 Local convergence, local optimum으로 가는 경우가 많다.
- policy evaluation 자체가 inefficient하고 variance가 크다.
Likelihood ratio/Score function policy gradient

Score function gradient estimator
: f(x)가 미분 불가능해도 gradient를 구할 수 있다.
- Unbiased but very noisey
- fixes that make it pratical
1) Temporal structure

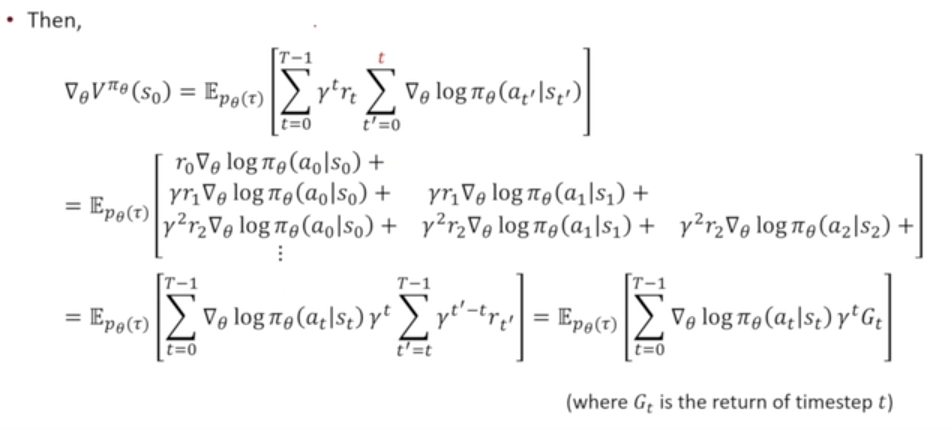
→ Monte-Carlo policy gradient(Reinforce) : Leverages likeliohhod ratio/source function and temporal structure
NLP와 같은 문제에 사용됨

2) Baseline

3) Alternatives to using Monte Carlo returns
Action - Value Actor-Critic

Trust Region Policy Optimization (TRPO)

- 너무 복잡해서 활용할 수 없음. → 더 간단한 PPO의 등장
Policy Gradient Summary
- 기존의 value-based 알고리즘보다 더 많이 쓰임
- policy parameterization을 어떻게 할 것인가에 대해 기존에 알고 있던 정보들을 활용할 수도 있다.
- RL을 실세계 문제에 적용할 수 있던건 REUNFORCE알고리즘이다.
- REINFORCE의 세 가지 트릭들과 PPO의 적용
- Understand where different estimators can be slotted in (and implications for bias/variance)
- Don't have to be able to derive or remember the specific formulas
강화학습 내용이 너무 넓고 어렵다.. 더 공부가 필요하다.